
1. Vector Database
1, vector database introduction
When we use image search to search for images or voice search to search for voice, what is stored and compared in the database is not the images and voice clips, but the “features” extracted by deep learning and other algorithms, which are usually 256/512 float arrays, and can be represented by vectors in math.
A vector database is a database used to store, retrieve, and analyze vectors. It is only called a database because it has the following characteristics:
a) Provide a standard access interface to lower the threshold of the user
b) Provide efficient data organization, retrieval and analysis capabilities. Users generally need to manage structured data while storing and retrieving vectors, i.e., support the ability of traditional databases to manage structured data.
2. Advantages of Vector Database
Give an example:
Q: What is the difference between using Embedding and just using full-text search on a database?
Answer: Suppose I have a text “Mice are looking for food” in my database. A user enters the query “‘cheese 🧀’”. The text search doesn’t recognize this passage at all; it doesn’t contain any overlap. But with Embedding, both passages are turned into vectors, and then a similarity search can be performed on the passage.
Since “mouse” and “cheese 🧀” are somehow related, the user is able to get results for the passage despite the lack of matching words.
3. Problems solved by vector databases
From a technical point of view, vector databases solve 2 main problems, one is efficient retrieval and the other is efficient analysis.
- Retrieval is usually image retrieval, such as face retrieval, human body retrieval, and vehicle retrieval, as well as Taobao’s product image retrieval, face payment.
(2) urban applications are also more, such as face collision, public security will be 2 similar modus operandi of the crime scene around the portrait to do comparison, to see which people at the same time in the 2 crime scene.
4. Some vector database products
Milvus, Pinecone, Vespa, Weaviate, Vald, GSI APU boards for Elasticsearch and OpenSearch, Qdrant
Details: [7 Vector Database Comparisons: Milvus, Pinecone, Vespa, Weaviate, Vald, GSI and Qdrant](https://link.juejin.cn?target=https%3A%2F%2Fwww.modb.pro%2Fdb% 2F516016 “https://www.modb.pro/db/516016“)
3. OpenAI ChatGPT API Documentation of Embedding
1. Embedding introduced by GPT
In the field of natural language processing and machine learning, “embeddings” refer to the process of transforming words, phrases, or text into a continuous vector space. This vector space is often called embedding space, and the resulting vectors are called embedding vectors or vector embedding.
Embedding vectors capture semantic information about words, phrases, or text, allowing them to be compared and computed mathematically. Such comparisons and computations are often used in natural language processing and machine learning for a variety of tasks, such as text categorization, semantic search, and word similarity computation.
In Chinese context, “embeddings” is often translated as “word vectors” or “vector representations”. These translations emphasize the characteristics of embedding vectors, i.e., words are converted into vectors and represented as points in the embedding space.
2. What is Embedding
Embedding is a vector (list) of floating point numbers. The distance between two vectors is used to measure the correlation between them. A smaller distance indicates high correlation and a larger distance indicates low correlation.
3. How to use GPT API?
Example request:
1 | curl https://api.openai.com/v1/embeddings \ |
Example Response:
1 | { |
Note: GPT will generate an embedding array of 1536 dimensions (array length is 1536) based on the string
3. Milvus vector database
1. Introduction
Milvus is a world-leading open source vector database that empowers AI applications and vector similarity search to accelerate unstructured data retrieval. Users get a consistent user experience in any deployment environment.
Milvus 2.0 is a cloud-native vector database designed with an architecture that separates storage from compute. All components in this refactored version are stateless, greatly enhancing system elasticity and flexibility.
2. Milvus Related Documents
- Zilliz Chinese Technical Zone:zilliz.gitee.io/welcome/
- Technical Video Collection:space.bilibili.com/1058892339M…
- GitHub:github.com/milvus-io/m…
- Docs:milvus.io/docs
- Official FAQ:milvus.io/docs/produc…
- Slack:milvusio.slack.com/join/shared…
- Towhee
- GitHub:github.com/towhee-io/t…
- Docs:docs.towhee.io/
- Online hosted version:Zilliz Cloud
4. GPT+Milvus to build a privatized knowledge base
1. Flowchart
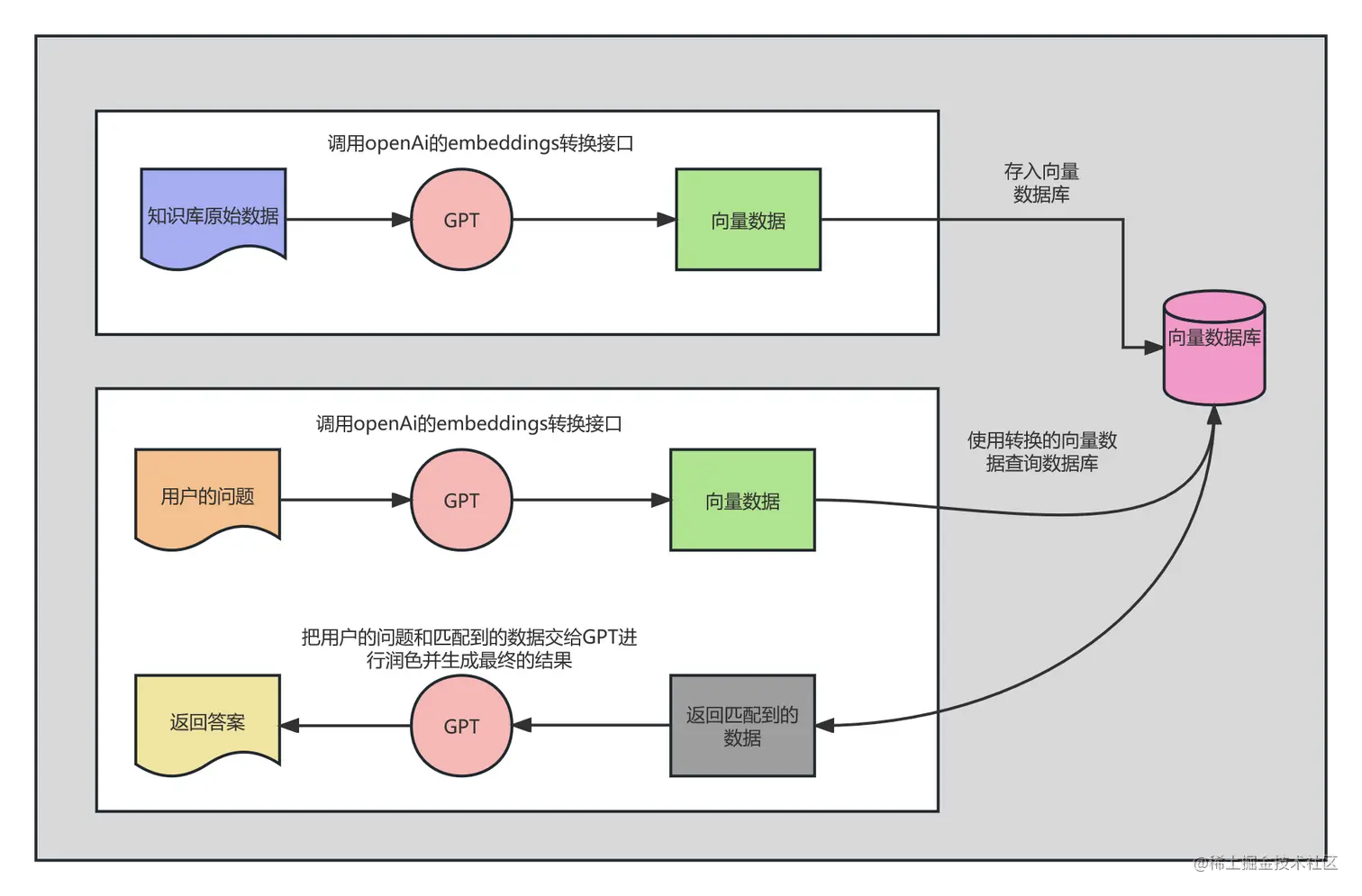
2. Detailed process realization
1, create a vector database collection (equivalent to database tables)
2, create the index of the collection
4, import the data call openAi convert to vector floating point data, the data text and vector floating point data stored in the collection
5, load the collection into memory for querying
6、User query call openAi to convert to vector floating point data, query the vector database to get the data text according to the vector floating point data.
7, take the user’s question and the data text from the vector database, write a prompt, hand it over to GPT for touching up, and generate the answer.
milvus-java:gitee.com/lgySpace/mi…





