The above has already covered how to design a highly available and stable gateway, so here are two of the more common ways to implement it.
Retries
In this case, I’m going to do a request retry for IO exceptions and request timeouts. First, we’ll add a retry function to the route filter that will retry the request in case of exceptions like the two above. Of course, we need to add some additional configuration parameters to set the number of retries and other information.
And the retry code, in fact, calls the doFilter method again to execute the logic in the route filter
Finally, we have our service request the backend service and set a long blocking sleep where the backend service is. The simple implementation of retries is relatively straightforward, provided of course that you understand all the previous code. Or at least understand the request forwarding piece of code
Flow limiting
Common algorithms for limiting flow are the token bucket algorithm and the leaky bucket algorithm. Here we can consider using both algorithms. At the same time, we need to configure the flow restriction rules in the configuration center. For example, the path or service to limit the flow. Also, depending on whether your service is a distributed service or a monolithic service, you also need to consider using different ways to store information. For example, if it is a distributed service, you need to use Redis, while if it is a monolithic, then consider using a local cache can be used, such as Guava or Caffeine. As usual, we first write an interface, which is used to get the corresponding flow restriction filter.
Once you’ve got the specified flow limiting rules, you can start thinking about getting down to writing how to do the specific flow limiting. For example, if we want to restrict the flow based on the path, the first information we need is the service and the request path. The first thing we need to know is the service and the request path, and we need to save the rules so that whenever a request comes in, we get the rules from the cache.
After obtaining the flow limiting rules, we can start to analyze how to carry out specific flow limiting methods. We get to the specified flow limit configuration, such as whether the service is distributed, whether the flow limit time and limit the number of times and so on, after the information, you can begin to write a specific flow limit code. For example, if the configuration found that the service is distributed, then use Redis, and then save the current request path and limit the number of times and other information.
So up to this point, the code for how to do flow limiting has been roughly implemented. After that, we can start testing our flow-limiting code once we’ve configured the configuration center information.
When we send an excessive number of requests using apifox, we see that the error is reported as follows Up to the current position we have implemented retry and flow limiting, then in the next article we need to implement fusing and degrading. Because actually flow limiting and fusing degradation go together.

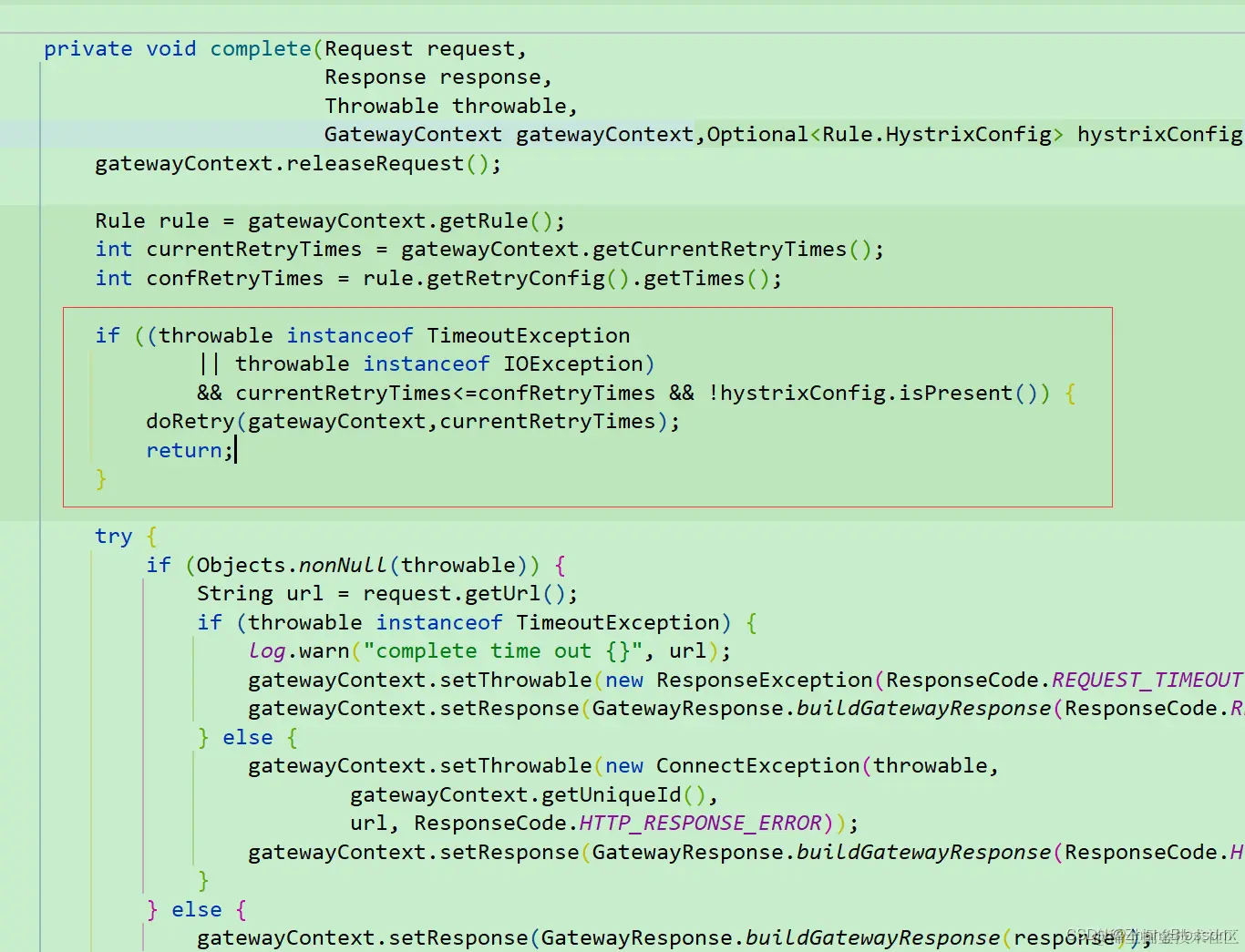 And the retry code, in fact, calls the doFilter method again to execute the logic in the route filter
And the retry code, in fact, calls the doFilter method again to execute the logic in the route filter The simple implementation of retries is relatively straightforward, provided of course that you understand all the previous code. Or at least understand the request forwarding piece of code
The simple implementation of retries is relatively straightforward, provided of course that you understand all the previous code. Or at least understand the request forwarding piece of code Up to the current position we have implemented retry and flow limiting, then in the next article we need to implement fusing and degrading. Because actually flow limiting and fusing degradation go together.
Up to the current position we have implemented retry and flow limiting, then in the next article we need to implement fusing and degrading. Because actually flow limiting and fusing degradation go together.