
Background
Currently, the development of large models has been very hot, and the training and fine-tuning of large models is also a key focus of various companies. However, the pain point of large model training is that the model parameters are too large, easily tens of billions, and it is basically impossible to rely on a single GPU to complete the training. So you need to multi-card or distributed training to complete this work.
I. Distributed training
1.1 The current mainstream distributed training of large models mainly includes two kinds:
- Data parallel training
- model parallel training
DeepSpeed
DeepSpeed is a distributed training tool provided by Microsoft, designed to support larger models and provide more optimization strategies and tools. For the training of larger models, DeepSpeed provides more strategies, such as Zero, Offload, and so on.
2.1 Basic Components
Distributed training requires mastering the basic configurations in a distributed environment, including node changes, global process numbers, local process numbers, total global process numbers, master nodes, and so on. All of these components are closely related to distributed training, and at the same time, there are also very big connections between the components, such as communication links and so on.
2.2 Communication strategy
Since it is distributed training, it is important to maintain communication between machines so that information such as model parameters, gradient parameters, etc. can be transferred.
DeepSpeed provides communication strategies such as mpi, gioo, nccl, and so on.
| communication strategies | communication role |
|---|---|
| mpi | It is a communication library for cross-boundary points, often used for distributed training on CPU clusters |
| gloo | It is a high-performance distributed training framework that can support distributed training on CPU or GPU |
| nccl | It is a GPU-specific communication library provided by nvidia and is widely used for distributed training on |
| GPU | nccl is a high-performance distributed training framework that supports distributed training on CPUs and GPUs. |
When we use DeepSpeed for distributed training, we can choose the appropriate communication library according to our own situation, usually, if it is GPU for distributed training, you can choose nccl.
2.3 Zero (Zero Redundancy Optimizer)
Microsoft developed Zero to address the limitations of data parallelism and model parallelism during distributed training. For example: Zero solves the problem of data parallelism into possible memory redundancy by dividing the model state (optimizer, gradient, parameters) during data parallelism (for normal data parallel training, all the parameters of the model are replicated on each machine); at the same time, it is possible to use a dynamic communication plan to share important state variables among distributed devices during training, so as to maintain the computational granularity and data communication in parallel.
Zero is a technique used for large-scale model training optimization, its main purpose is to reduce the memory footprint of the model, so that the model can be trained on the graphics card, the memory footprint is mainly divided into Model States and Activation two parts, Zero is mainly to solve the problem of the memory footprint of the Model States.
Zero divides the model parameters into three parts:
| States | Actions |
|---|---|
| Optimizer States | The data the optimizer needs to use when doing gradient updates |
| Gradient | The data generated during the backpropagation process, which determines the direction of the parameter update |
| Model Parameter | model parameter, the information “learned” from the data during model training |
2.4 Zero-Offload
CPUs are relatively cheap compared to GPUs, so the Zero-Offload idea is to put (offload) certain model states from the training phase into memory as well as CPU computation.
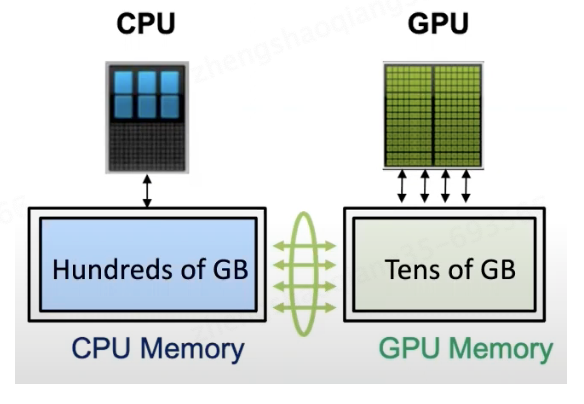
Zero-Offload does not want to minimize the memory usage and let the system computational efficiency decline, but if you use the CPU, you also need to consider the communication and computation problems (communication: communication between the GPU and the CPU; computation: too much CPU computation will lead to lower efficiency).
What Zero-Offload wants to do is to distribute compute nodes and data nodes on GPUs and CPUs, where compute nodes fall on whichever device performs computation, and data nodes fall on whichever device is responsible for storage.
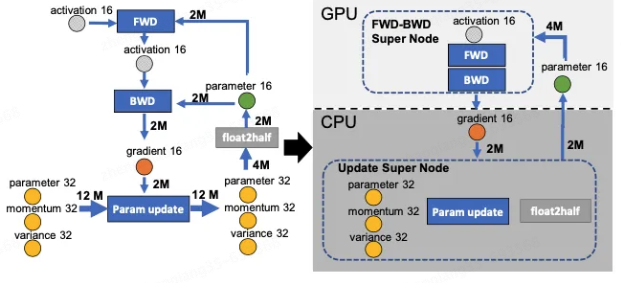
Zero-Offload slicing idea
There are four compute class nodes in the following figure: fwd, bwd, param update and float2half, the first two have roughly O(MB) computational complexity, B is the batch size, and the last two have O(M) computational complexity. In order not to reduce the computational efficiency, the first two nodes are placed on the GPU, and the last two nodes not only have a small computational amount but also need to deal with the Adam state, so they are placed on the CPU, and the Adam state is naturally placed in the memory, and in order to simplify the data graph, the first two nodes are fused into a single node, FWD-BWD Super Node, and the last two nodes are fused into a single node, Update Super Node. Super Node. as shown on the right side of the figure below, slicing along the two edges gradient 16 and parameter 16.
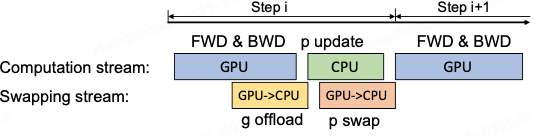
Zero-Offload computation idea:
The GPU performs forward and backward computation, transmits the gradient to the CPU for parameter update, and then transmits the updated parameters to the GPU.In order to improve the efficiency, the computation and communication can be parallelized.The GPU, in the back-propagation stage, can wait for the gradient value to fill up the bucket, and then once again compute the new gradient and once again transmit the bucket to the CPU.When the back propagation is finished, the CPU When the backpropagation is finished, the CPU basically already has the latest gradient values, similarly, the CPU also synchronizes the parameters that have been computed to the GPU when the parameters are updated, as shown in the following figure.
2.5 Mixed precision:
Mixed-precision training is a technique that uses both FP16 (half-precision floating-point number) and FP32 (single-precision floating-point number) precision in the training process. The use of FP16 can greatly reduce the memory footprint, thus allowing for the training of larger scale models. However, due to the lower precision of FP16, problems such as gradient disappearance and model collapse may occur during the training process.
DeepSpeed supports training with mixed precision, which can be activated by setting in config.json configuration file (“fp16.enabled”:true). During the training process, DeepSpeed will automatically convert part of the operations to FP16 format and dynamically adjust the precision scaling factor as needed to ensure the stability and accuracy of the training.
When using mixed-precision training, you need to pay attention to some issues, such as Gradient Clipping and Learning Rate Schedule. Gradient Clipping can prevent gradient explosion, and Learning Rate Schedule can help the model converge better.
III.
DeepSpeed facilitates the training and fine-tuning of large models with a limited number of machines, and it also has a lot of excellent performance to use, which can be continued to be excavated later.
Currently the mainstream way of training da models: GPU + PyTorch + Megatron-LM + DeepSpeed
Advantages
- Storage Efficiency: DeepSpeed provides a ZERO novel solution to reduce training memory usage, it is different from traditional data parallelism, it partitions the model state and gradient to save a lot of memory;
- Scalability: DeepSpeed supports efficient data parallelism, model parallelism, pipeline parallelism, and combinations of them, also referred to here as 3D parallelism;
- Ease of use: In the training phase, only a few lines of code need to be modified to enable pytorch models to use DeepSpeed and Zero.