As a backend developer, whether at work or in an interview, Distributed has always been a love/hate topic. It’s like a mysterious labyrinth that sometimes makes you lose your way and sometimes reveals amazing treasures for you.
Today, let’s talk about a lesser-known but important player in the distributed world that acts as a guard for the distributed system, protecting resources from being accessed at will - the distributed lock!
Imagine if there is no distributed locks, multiple distributed nodes at the same time into a shared resource access, like a group of hungry wolves gathered in front of a piece of meat, who want to take a bite, and finally made the meat lost a full, everyone can not eat.

And with distributed locks, it’s like putting a strong wall around this meat that only one wolf can cross and enjoy the flavor.
So how exactly does it do it? In this article, Xiao ❤ will bring you together to understand how distributed locks solve concurrency problems in distributed systems.
What is a distributed lock?
In a distributed system, a distributed lock is a mechanism for coordinating concurrent access to a shared resource on multiple nodes.
This shared resource can be a database, file, cache, or any data or resource that requires mutually exclusive access. **Distributed locks ensure that only one node can operate on the resource at any given moment, thus maintaining data consistency and reliability. **
Why use distributed locks?
1. Data Consistency
In a distributed environment, multiple nodes accessing a shared resource at the same time can lead to data inconsistency problems. Distributed locks prevent this from happening and ensure data consistency.
2. Preventing contention conditions
Contention conditions can occur when multiple nodes access a shared resource concurrently, which can lead to unpredictable results. Distributed locks effectively prevent contention conditions, ensuring that operations are performed in the expected order.
3. Limiting access to resources
Some resources may need to be limited in the number of simultaneous accesses to avoid overloading or wasting resources. Distributed locks can help control access to resources.
Problems to be solved by distributed locks
The core problem with distributed locks is how to coordinate among multiple nodes to ensure that only one node can acquire the lock while the others must wait.

This involves the following key issues:
1. Mutual exclusivity
Only one node can acquire a lock and the other nodes must wait. This ensures mutually exclusive access to resources.
2. Re-entry
This refers to the fact that after an outer function acquires a lock in the same thread, the inner recursive function can still acquire the lock.
To be clear, it means that when the same thread enters the same code again, it can get the lock again. Its purpose is to: ** prevent deadlocks from occurring due to competing conditions that result from multiple lock acquisitions in the same thread **.
3. Timeout release
Ensures that even if a node fails in the course of business, the lock will be released overtime, which prevents unnecessary thread waiting and resource wastage as well as deadlocks.
Distributed lock implementation
In a distributed system, there are multiple ways to implement distributed locks, just as there are different varieties of locks, each with its own characteristics.
- There are database-based locks, which are like chefs locking dishes in a cabinet with cutlery that everyone has to queue up to get.
- Then there are ZooKeeper-based locks, which are like a doorman for the entire restaurant, allowing only one person to enter, while everyone else has to wait at the door.
- Finally, there are cache-based locks, which are like a waiter who takes your seat on a first-come, first-served basis with a numbered card.
1. Database-based distributed locks
Use a row in a database table as a lock, and acquire and release the lock through a transaction.
For example, use MySQL to implement transaction locking. First create a simple table and create a unique index on a field (to ensure that when multiple requests are made to add a new field, only one can succeed).
1 | CREATE TABLE `user` ( |
Execute the following statement when you need to acquire a distributed lock:
1 | INSERT INTO `user` (uname) VALUES ('unique_key') |
Because the name field is uniquely indexed, when multiple requests submit insert statements, only one request succeeds.
The advantage of using MySQL to implement distributed locks is that they are reliable, but performance is poor, and the lock is **non-reentrant, and the same thread cannot acquire the lock **until it is released.
2. Distributed locks based on ZooKeeper
Zookeeper (zk for short) is an intermediate component providing consistency services for distributed applications with a hierarchical file system directory tree structure inside.
zk specifies that there can only be one unique file name under one of its directories. Its distributed locks are implemented as follows:
- Create a lock directory (ZNode) : First, create a directory in zk dedicated to storing locks, often called the lock root. This directory will contain all requests to acquire locks and the nodes used for lock coordination.
- Acquiring locks : When a node wants to acquire a lock, it creates an Ephemeral Sequential Node in the locks directory. zk assigns each node a unique sequence number and determines the order in which the locks are acquired based on the size of the sequence number.
- Check if the lock is acquired: After the node creates the Ephemeral Sequential Node, it needs to check if its node is the node with the smallest sequence number in the lock catalog. If yes, it means that the node has acquired the lock; if not, the node needs to listen to the deletion event of the node with smaller sequence number than it.
- LISTENING FOR LOCK RELEASE: If a node does not acquire a lock, it will set up a listener to watch for deletion events from nodes with smaller sequence numbers than it. Once the previous node (the node with the smaller sequence number) releases the lock, zk will notify the waiting node.
- Release lock: When a node finishes operating on a shared resource, it deletes the temporary node it created, which triggers zk to notify the waiting node.
zk distributed locks provide good consistency and availability, but are more complex to deploy and maintain, requiring careful handling of various boundary cases, such as node creation, deletion, and network partitioning.
Moreover, the performance of zk distributed locks is not so good, mainly because lock acquisition and release need to be performed on the Leader node of the cluster, which is slow to synchronize.
3. Cache-based distributed locking
Distributed caches, such as Redis or Memcached, are used to store lock information. The cache approach has higher performance, but it needs to deal with the high availability and consistency of distributed caches.
Next, we discuss in detail how to design a highly available distributed lock in Redis and several problems that may be encountered, including:
- deadlock problems
- locks released prematurely
- locks mistakenly deleted by other threads
- high availability issues
1) Deadlock problems
Earlier versions of redis did not have the setnx command to set a timeout parameter when writing a key, so you need to use the expire command to set the expiration time of the lock individually, which may lead to deadlock problems.
For example, setting the expiration time for a lock fails to execute, causing all subsequent lock grabs to fail.
Lua script or SETNX
To ensure atomicity, we can use a Lua script that ensures atomicity for both SETNX + EXPIRE directives, and we can also make clever use of Redis‘s SET directive extension parameter: SET key value [EX seconds][PX milliseconds][NX|XX], which is also atomic.
SET key value [EX seconds] [PX milliseconds] [NX|XX]
- NX: indicates that the
setcan only succeed if thekeydoes not exist, i.e., it guarantees that only the first client request can acquire the lock, while other client requests can only wait for the lock to be released. - EX seconds :Set the expiration time of
key, default unit is seconds. - PX milliseconds: set the expiration time of
key, default unit is milliseconds. - XX: sets the value of
keyonly if it exists.
In Go, the key code looks like this:
1 | func getLock() { |
2) Lock Early Release
The above scheme solves the atomicity problem of lock expiration and does not generate deadlock, but there may still be the problem of lock early release.
As shown in the figure, suppose we set the lock expiration time to 5 seconds, and the business execution takes 10 seconds.

While thread 1 is executing its business, its lock is released after its expiration date, at which point thread 2 is able to get the lock and also starts accessing public resources.
Obviously, this situation leads to public resources are not strictly serialized access, destroying the mutual exclusivity of distributed locks.
At this point, some of you may think that since the locking time is too short, we can just set the lock expiration time to be longer.
In fact, not, first of all, we can not know in advance the exact time of a business execution. Second, the access time of public resources is likely to change dynamically, so it’s not good to set the time too long.
Redisson Framework
So, we might as well give the locking thread an auto-renewal feature, i.e. check if the lock still exists every once in a while, and if it does, extend the lock to prevent it from expiring and being released early.
This feature requires the use of daemon threads, the current has an open source framework to help us out, it is - Redisson, which is implemented as shown in the figure:

When thread 1 succeeds in adding a lock, it starts a Watch dog watchdog, which is a background thread that checks every 1 second (configurable) if the business still holds the lock, to achieve the effect that the lock is not actively released by the thread and is automatically renewed.
3) Locks mistakenly released by other threads
In addition to locks being released early, we may also encounter the problem of locks being mistakenly deleted by other threads.
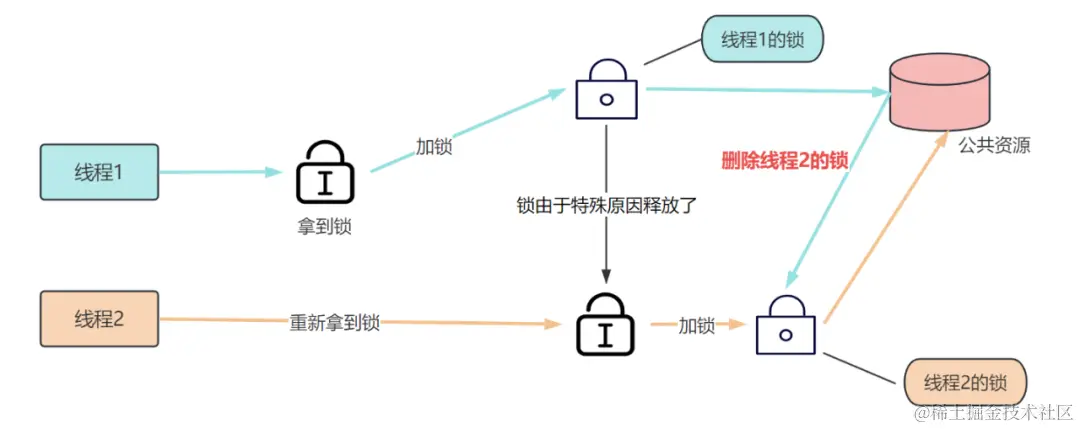
As shown in the figure, the locking thread 1 finishes executing its business and goes to release the lock. But thread 1 has already released its own lock, and the distributed lock is held by thread 2, so it will delete thread 2’s lock by mistake, but thread 2’s business may not be finished, resulting in an exception.
Unique Value
To solve the problem of accidental lock deletion, we need to add a unique identifier to each thread’s lock.
For example, when adding a lock, set the Value to the IP of the thread’s corresponding server. The corresponding Go key code looks like this:
1 | const ( |
This way, the problem of accidentally removing locks from other threads can be avoided by determining whether Value is the IP of the current instance when removing the lock.
To ensure strict atomicity, the above code can be replaced with a Lua script, as shown below:
1 | if redis.call( |
4) Redlock highly available locks
The previous several programs are based on the stand-alone version of the consideration, and the actual business of Redis are generally cluster deployment, so we next discuss the Redis distributed locks of highly available problems.
Imagine if thread 1 has a lock on the master master node of Redis, but it has not been synchronized to the slave slave node.
At this point, if the master node fails, the slave node is upgraded to the master node, and other threads can re-acquire the lock, ** at this point, there may be more than one thread to get the same lock. I.e., the distributed locks’ mutual exclusivity is broken. **
In order to solve this problem, the authors of Redis proposed a special algorithm to support distributed locks: Redis Distributed Lock, referred to as Redlock, whose core idea is similar to the election mechanism of the registry.

A Redis cluster deploys multiple master nodes, which are independent of each other, i.e., there is no data synchronization between each master node.
The number of nodes is odd, so every time a client grabs a lock, it needs to apply for the lock from these master nodes, and the lock will be successfully acquired only when it is acquired from more than half of the nodes.
Advantages, disadvantages, and common implementations
The above are the three commonly used distributed locking implementations in the industry, and their respective advantages and disadvantages are as follows:
- Database-based distributed lock: high reliability, but poor performance, not suitable for high concurrency scenarios.
- ** Distributed lock based on ZooKeeper **: provides good consistency and availability, suitable for complex distributed scenarios, but deployment and maintenance is complex, and the performance is not as good as the cache approach.
- Cache-based distributed locks: higher performance, suitable for most scenarios, but need to deal with the high availability of the cache.
Among them, the commonly used distributed locking implementations in the industry are usually cache-based approaches, such as Distributed Locking with Redis. This is because Redis has excellent performance and can fulfill the needs of most application scenarios.
Summary
Despite the twists and turns of the distributed world, with distributed locks, we are like the audience at a movie, where we can enter in an organized fashion, and the resources in the distributed system are like films waiting to be viewed one by one.
That’s the beauty of distributed! It may be loved and hated, but **it’s the diverse complexity of the tech world that makes our technological journey so much more exciting. **