
A chart to understand the SQL execution process
1. Introduction
Recently, I realized that no matter it is the first time to enter the job market, or the development students who have been working for many years. Although they have been working with databases (especially MySQL) for a long time, they know little or nothing about the execution process of SQL statements.
The execution process of MySQL is really a complex process, which involves multiple components working together, so it is easy to fall into confusion and misunderstanding during the interview or work process.
SQL Execution Process
So, in this article, I’m going to take MySQL’s common InnoDB storage engine as an example to introduce you to the execution process of SQL statements in detail. Starting from the connector, all the way to the transaction commit and data persistence.
Let’s start with a diagram:
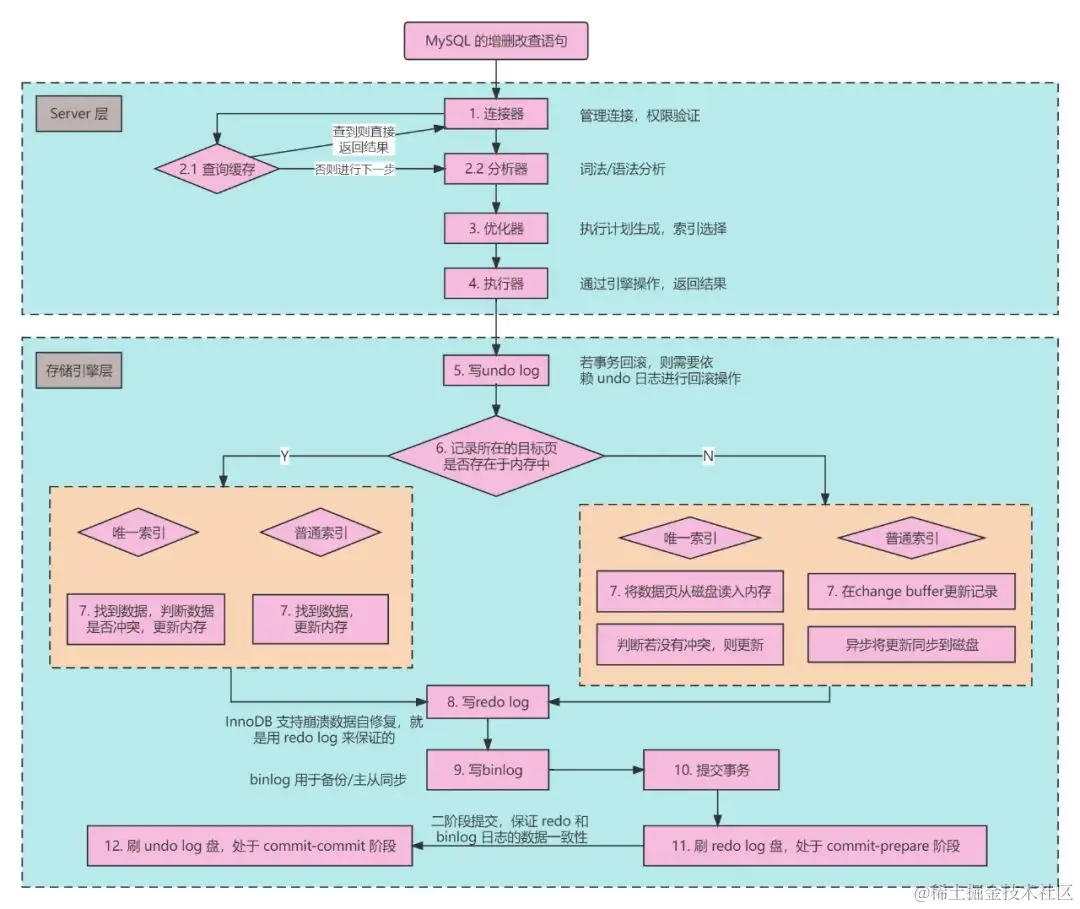
First, the client connects to MySQL Server and sends an add, delete, change, or query statement. When the Server receives the statement, it creates a parse tree for optimization.
When the optimizer optimizes the statement, it will evaluate the cost of various indexes, choose the appropriate index, and then call the InnoDB engine interface through the executor to execute the statement.
2. Specific Execution Flow

1. Connection Manager
The MySQL execution process begins with the connector. When a client requests a connection to MySQL, the connector is responsible for handling those connection requests.
It verifies the client’s identity and privileges, and then allocates a thread to handle the connection. MySQL creates a session for each connection thread, in which the client can send SQL statements to perform operations such as additions, deletions, and modifications.
2. Parser
Once the connection is established, the client can send SQL statements to be executed.
These SQL statements are first sent to the parser, whose job is to parse the SQL statement, determine if it is syntactically correct, and convert it into an internal data structure for subsequent use by MySQL.
If the SQL statement has syntax errors, the parser will return an error message to the client.
3. Optimizer
Once the SQL statement has been successfully parsed, the next step is to enter the realm of the optimizer.
The task of the optimizer is to evaluate different execution plans for the SQL statement and select the best one. It considers which indexes are available, which join methods are most efficient, and how to minimize the cost of the query.
4. Executor
After the executor receives the execution plan generated by the optimizer, it starts executing the actual query operation.
The executor follows the steps in the execution plan, calling the InnoDB engine-level logic and fetching data from the data table, then performing sorting, aggregation, filtering and other operations.
Eventually, the executor returns the results to the client.
5. write undo log

When an executor performs an operation that modifies data, MySQL’s InnoDB engine first opens a transaction to generate an undo log (also called a rollback log) for those modifications.
The rollback log is used to record data prior to modifications so that the original data can be recovered when the transaction is rolled back. If the transaction fails, MySQL can use the undo log to undo the changes that have been made.
6. Record Cache, Lookup Indexes
MySQL uses a record cache to store rows of data read from a data table. This cache speeds up access to frequently read data and avoids the overhead of having to read from disk each time.
When the data exists in memory, it only needs to be updated in memory; conversely, it may need to be read from disk and then updated on disk.
This depends on the type of indexes MySQL has, which can be categorized into two types:
- Unique indexes: index columns have unique values, null values are allowed for non-primary key unique indexes, and null values are not allowed for primary key indexes;
- Ordinary indexes: no special restrictions, duplicate values and null values are allowed;
When the SQL operation data reaches this step, InnoDB first determines whether the data page is in memory:
- In memory, determine whether the index being updated is a unique index. If it is a unique index, determine whether the update destroys the consistency of the data, if not, directly update the data page in memory; if it is a non-unique index, ** directly update the data page in memory**.
- Not in memory: determine whether the updated index is a unique index. If it is a unique index, because of the need to ensure uniqueness after the update, you need to load the data page from disk to memory immediately, and then update the data page; if it is a non-unique index, record the operation of updating the data ** to the change buffer, which will be updated to disk asynchronously when it is idle **.
change buffer
The change buffer is one of the features of the InnoDB engine. Before MySQL 5.5, the main purpose of the change buffer was to improve the performance of data insertion, which was also known as the insert buffer.
As we know, when a non-aggregated index is inserted, the data will be stored in the order of the primary key, so leaf nodes may need to access the data index page discretely, and the disk needs to be flushed each time the index page is updated. And each time reading and writing the disk will take a long time, so it leads to low insert performance.
While insert buffer is turned on, it will first determine whether the aggregated index page exists in the buffer pool, if it does, directly insert; if not, it will first be put into an insert buffer for sorting, and then merge (merge) to update the index page at a certain frequency.

As shown in the figure, the insert buffer combines multiple operations to reduce random I/O and reduce disk interaction, thus improving overall performance.
Since MySQL 5.5, the type of buffer for data deletion and modification has been added gradually and is uniformly called change buffer.
**In a nutshell, a change buffer is mainly used to cache secondary index additions, deletions, and modifications (IDUs) to reduce random I/O and to achieve the effect of merging operations. **
Unique indexes do not have a change buffer mechanism because they require immediate IO to disk to ensure that the data does not conflict.
8. Write redo log
During SQL execution, InnoDB also records all data modifications to the redo log.
The redo log is a cyclically written log file that records each step of a transaction to ensure data persistence. If the system crashes, InnoDB can recover uncommitted transactions based on the redo log to maintain data consistency.
Note that redo log is divided into prepare and commit states. When InnoDB writes changes to a data page to the redo log during the execution of a transaction, its state is prepare.
9. Writing the Binlog and Committing the Transaction
In addition to the redo log, MySQL also records a binlog.
The binary log records all executed SQL statements, not just data changes, which is important for data replication and recovery because it ensures that not only the state of the data is restored, but also the SQL operations that were performed.
When the InnoDB engine layer writes the redo log, it notifies the MySQL Server layer that the update operation has been executed. At this point, MySQL Server writes the executed SQL to the binlog and then notifies InnoDB that the redo log is in the commit state and the transaction was successfully committed.
Note that the success of a transaction commit is determined by whether or not it was written to the binlog. If it is written, even if MySQL Server crashes, you can recover from the redo log and binlog later.
3. redo log and binlog
As mentioned above, when a transaction commits, there are two phases, which we will summarize:
- When the data is updated, the data page in memory is updated and the update operation is written to the redo log, which enters the prepare state. At this point, the redo log enters the prepare state and notifies MySQL Server that the update is complete and ready to be committed;
- MySQL Server decides whether to write the updated SQL or data rows to the binlog according to whether the persistence mode is STATEMENT or ROW, and then calls InnoDB’s interface to set the redo log to the commit state and the update is complete.
Careful students may ask, why binlog only need to commit once, but redo to commit twice? And why do we need binlog when we already have redo log?
To answer this question, you need to start with the essential difference between the two types of logs.
redo log
The redo log is used to record transaction logs under the InnoDB engine, and supports self-healing of crashed data.
**If you write only binlog but not redo log, you may lose the data of the most recently executed transactions when MySQL goes down. **
binlog
The binlog records all changes made to the database at the MySQL Server level for data archiving, data backup, master-slave replication, and so on.
If you write a redo log and commit it directly without going through the prepare phase, this process can be used to recover data from the redo log in the event of a failure if MySQL deploys a master-slave node, **the master can recover the data based on the redo log, but the slave nodes will not be able to synchronize this part of the data **.

As you can see from the above figure, MySQL master-slave replication relies on the binlog of the Master node, the relay-log of the Slave node and 3 important threads.
log dump thread
When a slave node connects to a master node, the master node creates a log dump thread for it to read and send binlog contents. While reading the binlog, the log dump thread locks the bin-log on the master node until the reading is complete and the lock is released.
The master node creates a log dump thread for each of its slave nodes.
I/O threads
When a slave node binds to a master node, an I/O thread is created to connect to the master node and request the binlog from the master repository.
When the log dump thread of the master is listened to, the I/O thread saves the log to relay-log.
SQL thread
The **SQL thread is responsible for listening to and reading the contents of the relay-log, parsing it into specific operations and replaying them so that they are consistent with the main database. ** After each execution the thread in question will sleep and wait for the next wakeup.
The slave database will detect whether the bin-log log of the master database has changed in a certain time interval, and if it has changed, it will start the IO thread and continue to execute the above steps.
Conclusion
Thanks for reading and watching, see you in the next installment!
Feel free to like, share, and bookmark this page.