
Flow of the request
An HTTP request sent to a gateway and completing the entire lifecycle typically includes the following steps:
Client Request: The request begins on the client side, which sends the request via an HTTP request (e.g., GET, POST, etc.) to the entry point of the API gateway.
API Gateway Receive: The API gateway acts as the first point of receipt for the request, it listens for requests from the client, usually on port 80 (HTTP) or 443 (HTTPS).
Request Routing: The API gateway routes the request to the appropriate backend service based on the request’s destination path or domain information. This can be based on configured routing rules or dynamic routing based on the path in the request.
Request Authentication: Prior to routing, the API gateway may perform request authentication, including authentication, API key validation, access token validation, and so on. This ensures that only authorized clients can access the backend service.
Request Transformation: The API gateway may need to transform the data format of the request to ensure that the request matches the data format expected by the back-end service. This can involve data conversion or remapping of request parameters.
Load balancing: If there are multiple instances of the backend service, the API Gateway may perform load balancing to select an appropriate instance of the backend service to handle the request. This ensures that requests are evenly distributed to the back-end service.
Request Proxy: Once routing and authentication are complete, the API Gateway proxies the request to the selected backend service. This typically involves resending the request to the HTTP endpoint of the backend service.
Backend Processing: The backend service receives the request and performs the appropriate action based on the content of the request. This can be querying the database, processing business logic, generating a response, etc.
Response Transformation: The backend service generates the response and returns it to the API gateway, which may need to convert the response to the format expected by the client, perform data conversion, etc. The API gateway then converts the response to the format expected by the client, and returns it to the API gateway.
Response Delivery: Finally, the API gateway sends the processed response back to the client.
Response Validation: Before sending the response to the client, the API gateway may also perform response validation, including authorization checks, addition or modification of response headers, and security checks.
Response Delivery: Finally, the API Gateway delivers the response to the client, which receives it and performs the appropriate action.
Architecture Design
Referring to the design of the current mainstream gateways, there are SpringCloud Gateway as well as Zuul, both of them make heavy use of the idea of asynchronous programming in the underlying layer, and both of them also have a very important design on the network communication. For example, when I first looked at the source code for SpringCloudGateway, I saw a lot of use of Netty.
Since our gateway is self-developed, i.e., it is a separate service in its own right, we do not need to use a framework such as SpringBoot, we can directly use the native Java framework to write a variety of important code.
Network communication without doubt on the use of Netty can be.
At the same time, in the first article also mentioned, the gateway is required to use the registry, because our request specific last to forward to the route, is required to pull service information from the registry, the current registry: Zookeeper, Eureka, Nacos, Apollo, etcd, Consul. They have their own advantages and disadvantages, such as the Zk guaranteed Zk guarantees CP instead of AP, we know that the gateway is the first gateway to the application, we use Dubbo will use Zk, but for the gateway, availability is greater than consistency, so Zk we do not choose. Eureka and SpringCloud ecosystem have a relatively close connection, so if we use it, it will increase the coupling of our gateway and SpringCloud, not quite in line with the original intention of our self-research, so also do not choose. Etcd, although it is a generic key-value pair distributed storage system that can be well applied to distributed systems, but still no good advantage, of course, he is very lightweight. So it is not considered here. Consul and Etcd are more or less the same, so Consul is not considered here. Here I choose Nacos as the registry, Nacos first supports CP and AP protocols, and provides a good console to facilitate the management of my services. At the same time, the Nacos community is relatively very active, and there is more information on the Internet. At the same time, I have also read the source code of Nacos, which is elegantly written and relatively easy to understand. At the same time, I believe that more people will use Nacos, so I choose Nacos as the registry here. Of course, the above several registration center can be used, there is no particularly obvious advantages and disadvantages, they also have their own appropriate occasions, specific occasions for specific analysis, mainly to analyze their own team to understand more or suitable for which kind of registration center. Configuration center, SpringCloud Config, Apollo, Nacos.
Here it is clear that still choose Nacos, because Nacos is not only a registration center is also a configuration center. Therefore, by choosing Nacos, we can minimize the introduction of unnecessary third-party components. So for the technology stack, the following technologies were chosen:
- Java
- Netty
- Nacos
Design Points
There are some important design points to consider when designing a high performance gateway
Serialization The use of parallelism naturally has its benefits in terms of speeding up the processing of some services, but because it involves operating system and thread level operations, there are some scenarios where the use of serialization can be used to optimize performance. For example, for less time-consuming scenarios with high performance requirements, we can use serialization. For scenarios that take a long time and have no dependencies between tasks, such as RPC remote calls, we can use parallelization.
Asynchronization Using asynchronous processing improves performance by allowing the gateway to process multiple requests at the same time without being blocked. This can be achieved by employing asynchronous frameworks, event-driven programming models, or multi-threaded/multi-process processing. We can consider asynchronization in the following places: ** request forwarding asynchronization, request response asynchronization, plugin filtering asynchronization. ** **The mode of simultaneous asynchronization can be considered as single asynchronous mode or double asynchronous mode. ** This means that the time when the sender receives and sends data does not have to be completely synchronized. Where single asynchronous mode means that only one direction is available for data transfer at the same time, while double asynchronous means that both directions are available for data transfer, and then the speed of data transfer will be much higher. We can consider using single asynchronous mode for plugin filtering and double asynchronous mode for request response. And double asynchronous mode is suitable for application in the downstream server performance is not very high scenarios. Not very understanding of single-asynchronous and double-asynchronous can first Google simple understanding.
Cache Cache commonly used response data to reduce the load on the back-end service. A proper caching strategy can significantly improve response time and reduce resource usage. Consider using a cache like Caffeine, the gateway recommends memory-level caching.
Throughput In moments of high traffic, we generally need to do some peak shaving and flow limiting. For example, the use of some message middleware such as RocketMQ, but in the self-developed cache, the use of message middleware will increase the coupling of our system, and message middleware will also need to be transmitted over the network, which will prompt the RT time of our system. So we need to consider using a local buffer, such as using Disruptor.
Reasonable Configuration of Threads We all know that there are CPU-intensive and IO-intensive tasks. So reasonable configuration of the number of threads can also improve our project performance. For example, for common CPU-intensive tasks, we will set the number of threads to n+1, and for IO-intensive tasks, we will set the number of threads to 2n. All these are to improve our performance to some extent.
Project Architecture
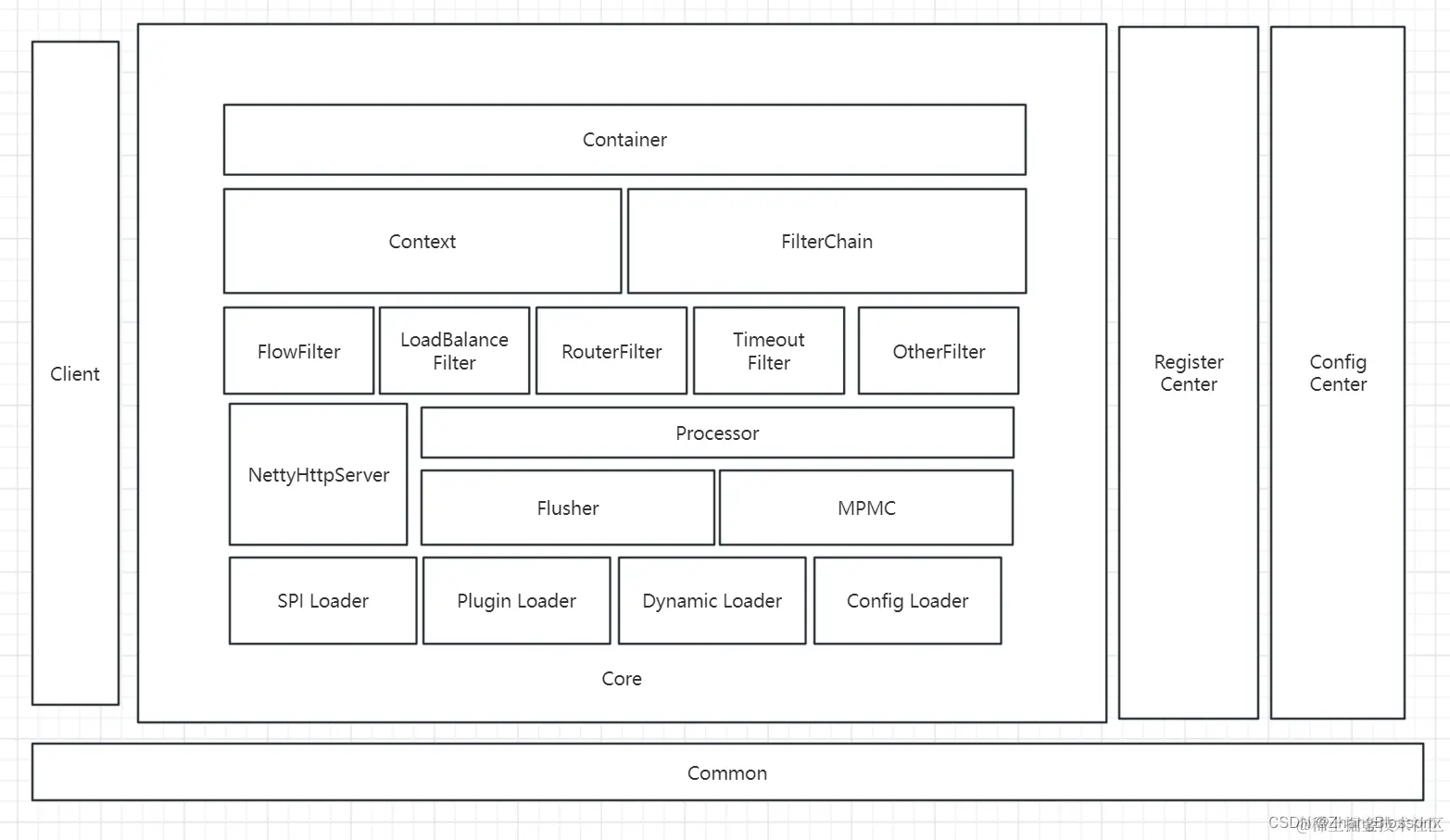 Common: Maintain public code, such as enumeration Client: Client module to facilitate our other modules to access the gateway Register Center: Registration Center module Config Center: Configuration Center module Container: contains the core functionality Context: request context, the rules FilterChain: through the Chain of Responsibility mode, chained execution of filters FlowFilter: flow control filters LoadBalanceFilter: load balancing filters RouterFilter: routing filters TimeoutFilter: timeout filters OtherFilter: other filters NettyHttpServer: receive external requests and flow internally Processor: Background request processing Flusher: Performance optimization MPMC: Performance optimization SPI Loader: Extension Loader Plugin Loader: Plugin Loader Dynamic Loader: Dynamic Configuration Loader Config Loader: Static Configuration Loader
Common: Maintain public code, such as enumeration Client: Client module to facilitate our other modules to access the gateway Register Center: Registration Center module Config Center: Configuration Center module Container: contains the core functionality Context: request context, the rules FilterChain: through the Chain of Responsibility mode, chained execution of filters FlowFilter: flow control filters LoadBalanceFilter: load balancing filters RouterFilter: routing filters TimeoutFilter: timeout filters OtherFilter: other filters NettyHttpServer: receive external requests and flow internally Processor: Background request processing Flusher: Performance optimization MPMC: Performance optimization SPI Loader: Extension Loader Plugin Loader: Plugin Loader Dynamic Loader: Dynamic Configuration Loader Config Loader: Static Configuration Loader
Process Design
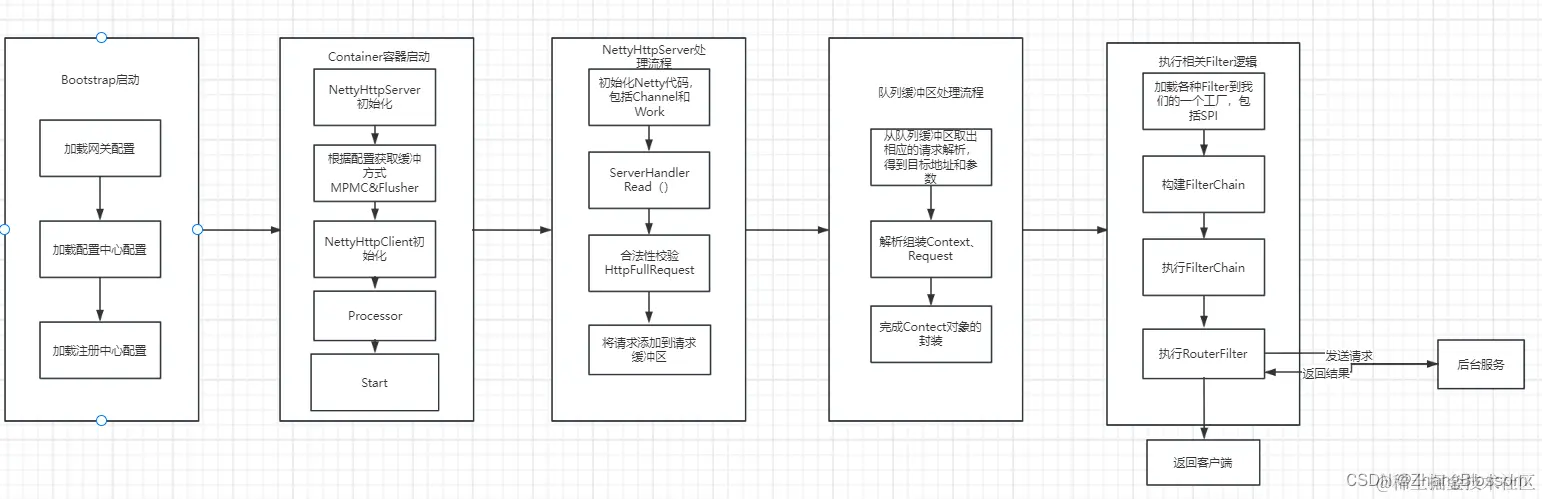 With this more detailed processing flow above, we can probably start preparing to write the code. Stay tuned for the following, which will start the actual writing of the code.
With this more detailed processing flow above, we can probably start preparing to write the code. Stay tuned for the following, which will start the actual writing of the code.
