
This article does not have a specific business implementation, but only for how to design a highly available, stable gateway to list some of the thinking. If you are not interested in the concepts, you can just skip this article.
High Availability Analysis
High Availability (HA) is the ability of a system or service to maintain continuous operation and availability in the face of a variety of failures, errors, or adverse conditions. High availability is an important goal in the design of computer systems, networks, and applications to reduce system downtime and ensure business continuity to meet the needs of users and customers. Why do we need high availability we can cut through the following points:
- Business Continuity: In today’s digital world, many organizations rely on computer systems and networks to support their core business. Downtime of systems can lead to business interruption, damage to reputation, financial loss, and loss of customer trust. High availability ensures that systems are continuously available and helps maintain business continuity.
- :: User experience: users expect to be able to access applications and services anytime, anywhere. If systems are frequently unavailable or have long response times, the user experience will suffer and users may look for alternatives. High availability improves user experience and increases user satisfaction.
- :: Fault tolerance: Hardware failures, software bugs, natural disasters, or human error can lead to system outages. A high-availability design allows the system to tolerate these failures and automatically switch to an alternate device or data center to maintain continuity.
- :: Data protection: Data is a critical asset of an organization, and loss or corruption of data can cause significant damage to operations. High-availability systems often employ data redundancy and backup strategies to ensure data integrity and availability.
The gateway, as the first gateway for requests, is one of the most frequently used services in the project, so the availability of the gateway greatly determines the reliability of our services, and to a certain extent affects the user experience. Therefore, for the design of the gateway, we need to ensure its high availability as much as possible, and for high availability, and can be realized from the following points of entry:
- Hardware redundancy: Use redundant components, such as dual power supplies, hot-swappable hardware, disk arrays, etc., to reduce the impact of hardware failure on the system.
- Software redundancy: Use load balancing and failover mechanisms to ensure that applications and services can run on multiple servers and that traffic can be switched to another server when one fails.
- Data backup and recovery: Implement a regular data backup strategy to ensure data security and availability. Backup data can be used to restore the system in the event of a disaster.
- Monitoring and automation: Use monitoring tools to monitor system performance and availability in real time. Automating system management and failback operations can help reduce system downtime.
- Multi-data center deployments: Use data center deployments across multiple geographic locations to increase the fault tolerance of the system so that even if one data center fails, the others can continue to provide service.
What is better understood here is software redundancy, which is the clustered approach to deploying our services. This way, assuming that our service has a 90% probability of uptime, if we have a cluster of three service instances, the high availability is: 1- 0.1 * 0.1 * 0.1 = 99.9%.
Software Architecture
So for one of our services, the service deployment might look like this, the following is the deployment architecture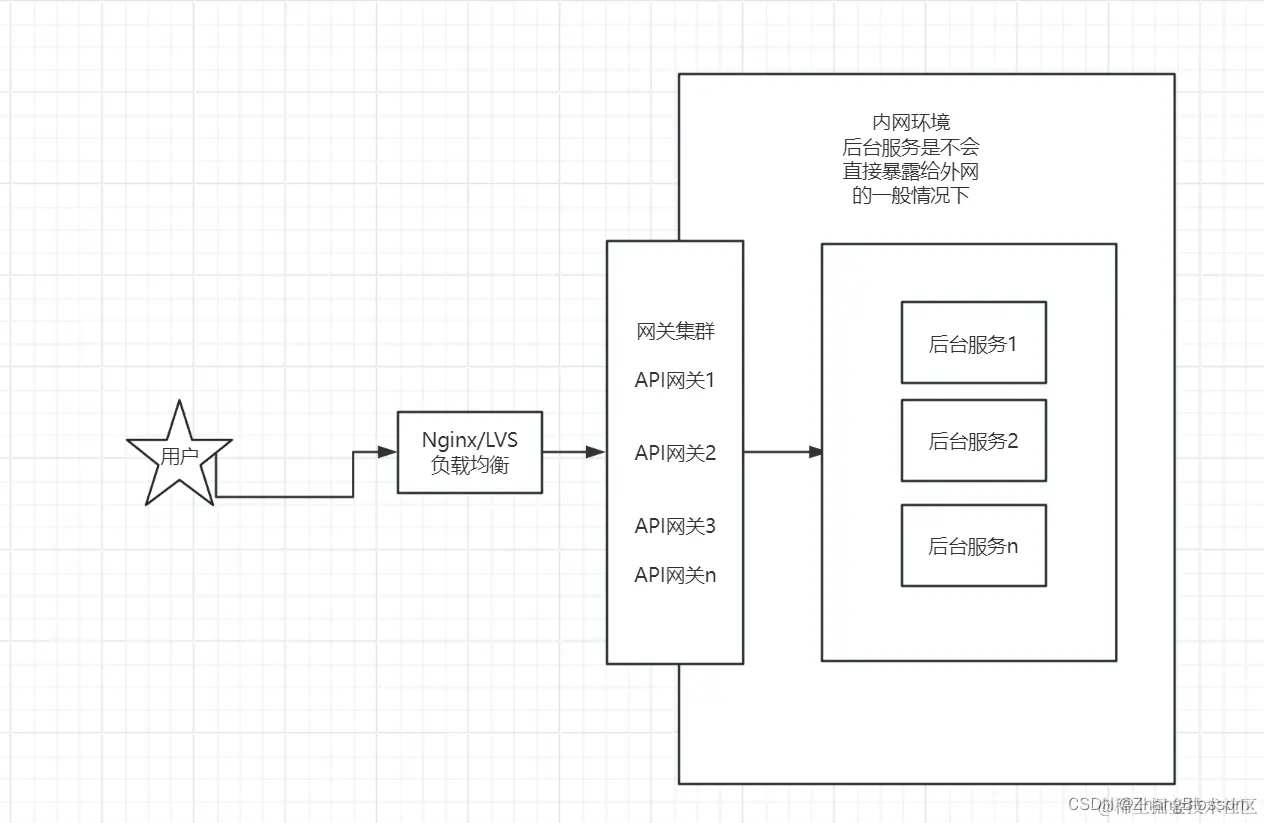 In order to further realize high availability, we also need to solve the case of manual switching of the crashed service manually, that is, to realize the hot-switching of the master and the backup, and to realize the switching automatically when the service fails. We can determine whether the service is alive through regular heartbeat detection. If the service is not alive, then we will remove the service from the list of registries and so on, so that it will not be accessed for the time being, and then we carry out repair and maintenance of the downed service, and restart the project.
In order to further realize high availability, we also need to solve the case of manual switching of the crashed service manually, that is, to realize the hot-switching of the master and the backup, and to realize the switching automatically when the service fails. We can determine whether the service is alive through regular heartbeat detection. If the service is not alive, then we will remove the service from the list of registries and so on, so that it will not be accessed for the time being, and then we carry out repair and maintenance of the downed service, and restart the project.
Heartbeat detection
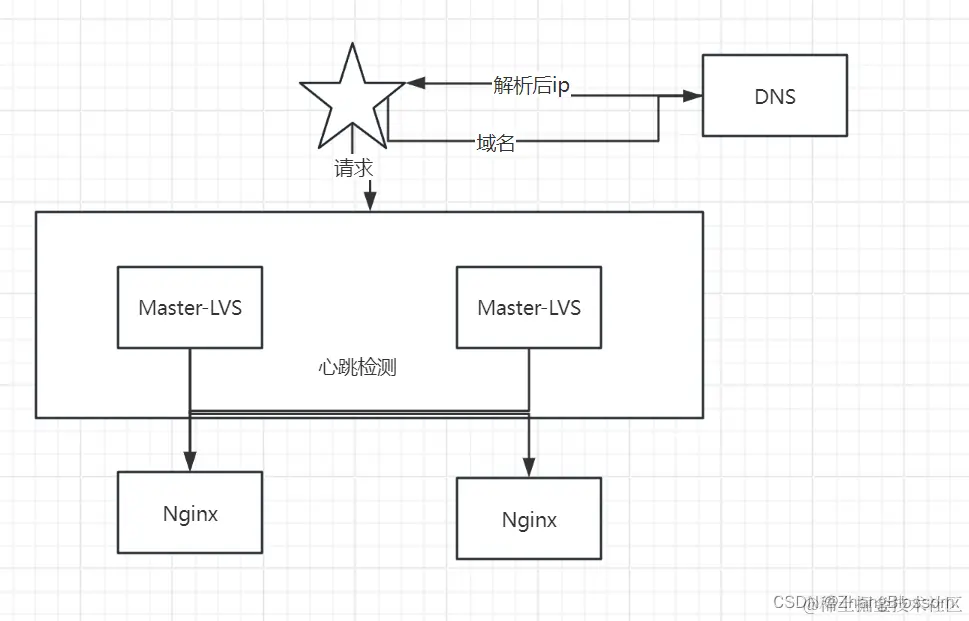
Auto-recovery
Similarly, when our service has already had a problem that caused it to go offline, and we want the service to start automatically, rather than having us manually start it again, we can make the service start automatically a certain number of times through scripts, etc., and then we’ll manually intervene if that doesn’t work.
Fuse Degradation
At the same time, in order to further realize the high availability of the gateway, we also need to realize the meltdown function. Here we can refer to the realization of the idea of hystrix. hystrix provides two concepts, namely, fusion and degradation, which is also a problem I encountered during my interview with Xiaomi. Never confuse these two concepts. Circuit Breaker is used to prevent constant requests for a failed service in a distributed system, it stops requests for the failed service for a period of time to allow the service time to recover. This helps to prevent the system from running out of resources due to constant requests for faulty services and protects the availability of the system.。 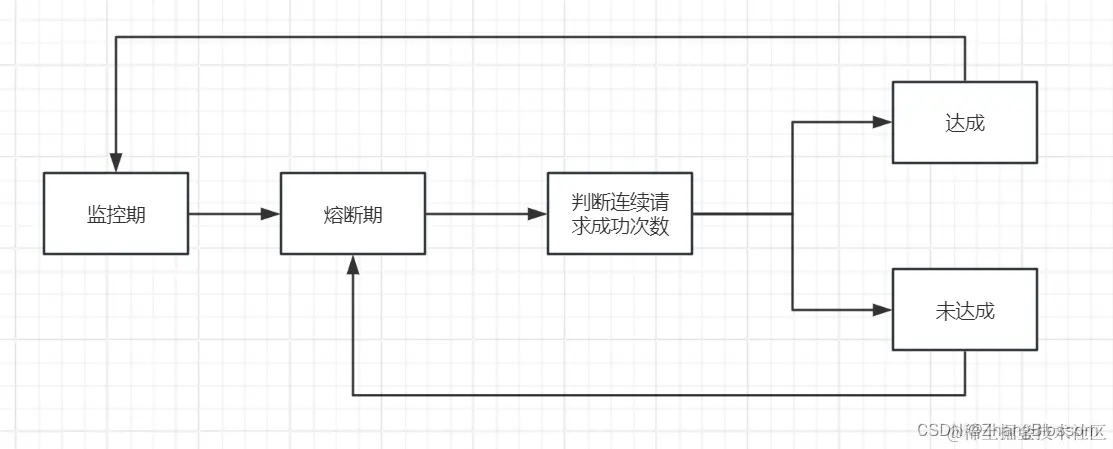
Fallback is another key feature of Hystrix that allows you to define alternate operations or responses to be provided to the user or system in the event that the primary operation (typically an invocation of an external service) fails or times out. A degraded operation is typically a simplified, non-failure operation that ensures that the system is still able to provide some level of service in the event that the primary operation fails. By degrading, you can provide a better user experience and provide useful information or services even if the primary operation fails.
Interface retries
It’s not that failing once might not really work, we can retry a certain number of times.
Isolation
Isolation means splitting the system or resources. System isolation is to limit the propagation range and influence range when a system failure occurs, i.e., there will not be a snowball effect after the failure, so as to ensure that only the service that has gone wrong is unavailable, while the other services are still available.
- :: Network security: by placing gateways between different networks, it is possible to restrict potential threats, malicious traffic or unauthorized access to protected networks. This helps reduce the risk of network attacks such as intrusions, malware propagation and data leakage.
- :: Access control: Gateway isolation can be used to manage network access to ensure that only authorized users or devices are able to access specific network resources. This helps protect sensitive data and systems from unauthorized access.
- Network performance: Network performance and traffic management can be improved by separating networks. For example, different departments or applications can be located in different subnets to prevent traffic conflicts between them, thus improving overall network efficiency.
- Isolated Problem Troubleshooting: Dividing the network into smaller areas makes it easier to identify and resolve network problems. If the problem occurs in a specific subnet, administrators can more quickly determine the root cause of the problem without affecting the entire network.
There are also more ways to isolate, thread isolation, process isolation, cluster isolation, room isolation, read/write isolation, fast/slow isolation, motion isolation, and crawler isolation. We commonly use ThreadLocal is thread isolation, we also mainly analyze and explain this point. For example, our services can be divided into core services and non-core services, then we can isolate the two services above the thread pool. That is, the core thread pool and non-core thread pool to let them to provide thread support respectively.
Pressure Testing and Profiling
“Pressure testing” is the practice of load testing a system, application, or network to determine its performance, stability, and reliability under varying load conditions. Pressure testing is usually performed by simulating a large number of users or requests to assess the performance limits of a system to ensure that the system will meet performance requirements in real-world use. Pressure testing can help identify performance bottlenecks, memory leaks, response time issues, and other performance-related problems in a system. Such tests are performed prior to development, testing, and production deployment to ensure that the system will function properly under varying workload conditions.
A “pro-forma” (also known as an emergency response plan or crisis management plan) is a document or plan designed to set out actions and procedures to be taken in the event of an emergency. It includes ways to respond to different types of emergencies or crises in order to minimize damage, ensure the safety of employees and customers, and restore normal business operations. A plan usually includes how to respond to various emergencies such as fires, natural disasters, cyber-attacks, data breaches, supply chain disruptions, and so on. The plans are usually prepared by the organization’s emergency management team or crisis management team and need to be updated and tested regularly to ensure their effectiveness.
In the technical realm, stress testing and preplans can also be related. While a stress test can help an organization determine how well its systems will perform in response to high loads or emergencies, a preplan can specify action steps to be taken in the event of a technology failure, cyberattack, or other technology-related crisis situation. These actions may include system maintenance, restoration of backup data, notification of relevant parties, or other technical measures. As such, both stress testing and preplanning are important tools and plans to ensure that systems and organizations can be operated and managed properly in a variety of situations.
Multi-Room Disaster Recovery and Dual-Activity Data Centers
Multi-Room Disaster Recovery (DR) and Dual-Active Data Centers are two strategies used to improve the high availability of systems and applications. They combine multiple data centers or server rooms to guarantee continuous availability of services in the event of a failure or disaster. Here’s how they guarantee high availability:
Multi-room disaster recovery (Disaster Recovery):
- Data redundancy: data is typically replicated to different server rooms to ensure availability for data backup and recovery. This can be accomplished through methods such as database replication, backups, and off-site storage.
- Automatic failover: Multi-room disaster recovery typically uses an automatic failover system, which automatically redirects traffic to the secondary data center when one data center fails to maintain service continuity.
- Hot standby: Standby data centers are usually hot standby, meaning they are ready to receive traffic and run continuously to reduce switchover time.
- Regular drills: The organization conducts regular disaster recovery drills to ensure that in the event of a disaster, personnel understand how to switch over to the secondary data center and that the system recovery process is working.
Dual-Active Data Centers (Active-Active Data Centers):
- Load Balancing: Traffic is often distributed to different data centers to ensure load balancing. This can be achieved through load balancers and DNS resolution.
- Data Synchronization: Data is synchronized in real-time across multiple data centers to ensure data consistency. This can be achieved through mechanisms such as database replication, file synchronization, and message queuing.
- Redundant Infrastructure: Dual-living data centers typically have redundant infrastructure for networks, storage, servers, etc. to ensure that in the event of a failure in one data center, traffic can be seamlessly switched to the other data center.
- Automatic failover: When one data center fails, the load balancer will usually automatically switch traffic to the other data center to ensure service continuity.
- Performance monitoring: A real-time performance monitoring system can help detect failures and problems and trigger automatic failover.
One important solution for multi-computer room disaster recovery here is: two locations and three centers, co-location disaster recovery and off-site disaster recovery. Two locations and three centers means: production center, co-location disaster recovery center, and off-site disaster recovery center. Here the off-site disaster recovery needs to consider the reasonable data replication/backup technology. For this data backup solution, it needs to be combined with the specific communication time and the maximum tolerable recovery time for users.
Dual-activity data centers are not quite the same as disaster recovery and backup centers. The former is always in working condition, while the latter is used in case of failure. Of course, dual-active data centers are difficult to implement, and there is no specific implementation plan in China, but you can store this knowledge in your head.
Exception Handling Mechanism
Exception handling mechanisms can help us locate problems and analyze them statistically. There are usually two types of exception mechanisms, divided into human and machine. People: users, operations, development, etc. Machines: processing according to the program status code There are many ways to warn of exceptions, which can be handled according to the needs of the team. For example, simply send an email, or the company’s internal IM system for notification. It is also possible to use phone calls and SMS to notify in a safer way. The gateway, as the portal for requests, also needs to handle exceptions. The gateway needs to do the following exception handling:
- Uniform management of exception codes
- Exception handling for collection, specific business should focus on the business itself
- The message corresponding to the exception status code should be handled by the gateway in a unified way
And for exception handling, we can use high fault-tolerant retries to handle it. Retrying is a means to improve the fault tolerance of the system.
Retry
Retries have some advantages and disadvantages. Some of them are that they are easy to implement, and if the problem is due to a network problem, retrying after a quick network recovery is the best solution. The downside, of course, is that retrying brings double the amount of traffic to the service system, which may result in a direct crash of the service. The solution is to actively calculate the success rate of the service, the success rate is too low, then directly do not retry. The success rate here can actually be calculated using counting and other methods.
Automatic switching between primary and secondary services
There may be some problems with single service retries. So can we consider proactively switching between master and backup services? That is, when a request to service A fails, we actively switch and send the request to service B (the backup), so that it does not cause a double hit on A. But this switching, as well as retrying, leads to a degradation of the user experience because the response time increases. Also, if the primary service can’t handle the traffic because it’s too heavy, there’s a high probability that the backup service can’t handle it either. At the same time, most of the time we are using the main service, then the backup service there is a waste of resources. Of course, if the backup is for core scenarios such as order payment, the backup is still very important.
Dynamically cull or recover abnormal machines
All Services and Storage, Stateless Routing [Difference between stateless and stateful routing](https://link.juejin.cn?target=https%3A%2F%2Fblog.csdn.net%2FZhangsama1%2Farticle%2Fdetails% 2F134222718%3Fspm%3D1001.2014.3001.5502 “https://blog.csdn.net/Zhangsama1/article/details/134222718?spm=1001.2014.3001.5502“) This is done like this The benefit is to avoid a single point of risk where one service hangs and brings the whole cluster down. And since our log monitoring and other systems are generally not particularly large in number, using them isn’t inherently completely reliable. So we use stateless routing here, directly distributing requests randomly to the background services.
Support for parallel expansion. Encountering heavy traffic scenarios, support for adding machines to expand capacity The way this is realized is that when we monitor heavy traffic, or CPU spikes, we can expand capacity through the function set up earlier.
Automatic Rejection of Abnormal Machines After our routing service finds that the anomaly rate of requests for a service reaches the value we set, we will reject the service. We will then send out some trial requests, and if it passes the trial, we will recover the service.
Timeout considerations
In the traditional case, we usually set a timeout period. If the timeout is set too long, it will cause our worker threads to be occupied by blocking for a long time, and over time, more and more threads will not be available, and service failure will occur. If the setting is too short, it will lead to a direct timeout without processing the request, resulting in a waste of resources and although the processing is successful, but the return is a processing failure. So we will set a timeout for all services according to a uniform way is certainly not reasonable, so we need to consider some strategies to solve this kind of problem. Currently I understand the direction of the solution are: 1: fast and slow separation Literally, we can be in accordance with the services need to deal with different time, separate deployment, separate set their timeout.
2: solving synchronization blocking waiting For some blocking requests, such as downloading IO resources and other ways, it will lead to a long time in the system in the waiting state of resources, can not respond to new requests, it will cause us a certain waste of resources. Here our solution can be solved by using IO multiplexing through asynchronous callbacks. In fact, I designed the gateway itself to use CompletableFuture way to deal with, that is, asynchronous processing. Here asynchronous processing only improves the throughput rate of the system, but the user experience is still not prompted. In fact, you can continue to understand the concept of “concurrent”. Is a similar way to write synchronous code to achieve asynchronous callback mechanism (the company’s work requirements to go).
3: anti-re-entry is also known as idempotence processing. Because if your request waits a long time or not processed, the user is likely to click twice, then it will cause the request to re-enter, so we must do a good job of idempotence. The solution is distributed Redis, locks, re-entrant locks, unique order numbers with bitmap and so on.
Service design
Service degradation, automatic shielding of non-core branch exceptions 1: For the service core link, we have to focus on monitoring, and set a longer timeout time 2: For the service non-core environment, we set a shorter timeout time
Service decoupling, physical isolation 1: service separation, large services are split into small services 2: light and heavy separation, physical isolation
Fault tolerance at the business level, human error is unavoidable. Even with a perfect monitoring system, there is no guarantee that there will be no errors, so one needs to solve this problem at the system level. For example, we can solve the problem from the top of the business, for the wrong configuration information, directly report errors, which requires the development of a set of intelligent configuration detection system for different services.
